A computer room in 1985. How a context window actually works. Grep as a net thrown into the ocean. Three evolutions of markdown, three versions of the same problem. A knowledge map, not a flat file.
I won a computing competition when I was twelve. The prize was a Saturday morning each week in the computer room at one of the universities near where I lived, and for that year my mother drove me across town and dropped me off in a place that, to me, felt approximately as exciting as a lunar landing.
I do not remember the make of the machine. I remember the terminals, because they were impossible to forget. Cathode-ray tubes glowing in the particular shade of monochrome green anyone over forty-five recognises instantly. Mechanical keyboards that felt like typing into a filing cabinet.
And, most strangely of all from the perspective of a child who had already used home computers that saved to cassette tape, the storage medium was punch cards. You wrote your program, punched it onto a stack of cards, and fed the stack back into the reader to run it. I can still see it clearly, forty years on. The slight anxiety of dropping a stack on the floor and reassembling it in the right order. The clean mechanical sound of cards being fed. The improbable fact that the holes in some rectangles of cardboard added up to working software.
I have been thinking about that room a lot recently, because I am starting to suspect we are all back in it.
The shape of the interaction has not really changed. We write our instructions on a flat surface, hand the stack to a machine, and wait to see what it does with them. The cards are now markdown files (instruction documents, skills, rules, system prompts), but the medium is the same: long blocks of text composed by a human, fed wholesale to a machine that reads them top to bottom and acts on what it sees. Different cards, different reader, same primitive interface.
Engineers are problem-solvers by temperament. When the industry started using AI systems seriously, the first problem we hit was the same one: there was no clean way to give context to the process we were trying to run. The agent needed to know something about the project before it could produce anything sensible. So we reached for the simplest format that could possibly work, and that turned out to be the markdown document. Markdown is structured but lightweight, opinionated about the few things it cares about, and is plain text, which means anything can read it. Within months it had become the format of choice.
How a context window actually works
It is worth pausing here on what is happening underneath an agent session, because every approach the industry has tried so far is in trouble for the same reason: it treats the context window as a place to dump everything that might be relevant, rather than as something engineered for a specific job.
LLMs themselves are stateless. The model has no memory between requests. Every time you type a message into a coding agent, the entire conversation up to that point is packaged on your machine, POSTed to the model over HTTP, and read by the model from the top to the bottom — system prompt first, then tool definitions, then every previous turn, then your latest message — before a single token of response is produced. Then the connection closes. The next turn is another full payload, the entire conversation again, plus the latest exchange tacked on the end. Anything that looks like memory in a coding agent is the harness around the model writing state back into the next request on your behalf. The model itself has no idea what was said five minutes ago.
What that means in practice is that every irrelevant rule, every contradictory instruction, every backward-forward debugging trail still sitting in the conversation is being re-read by the model on every single turn. It is not in some background memory the model can ignore. It is in the input the model has to reason over, every time, weighing on the relevance signal in the part that actually matters.
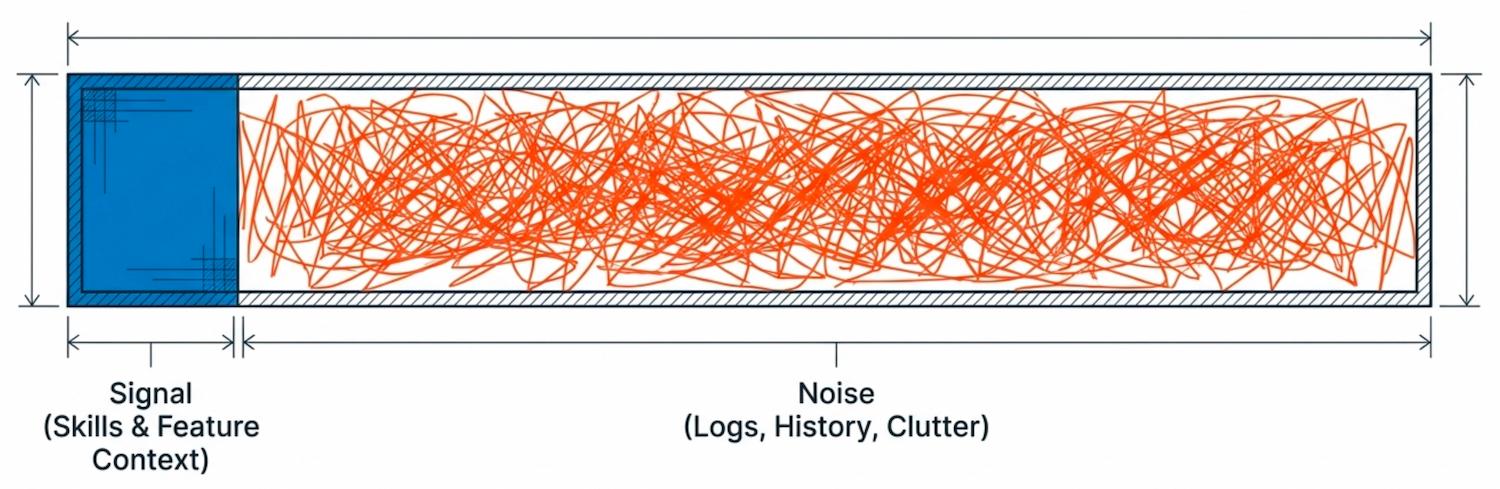
Every token in the context either earns its place or weakens the signal. That is the underlying discipline, and how teams apply it falls into three rough categories.
Ideal. The context is built fresh for the task at hand. It carries a clear statement of the intention, the critical information the agent needs to act on it, and a clean instruction to execute. Nothing else. It is used once, the work is produced, and the context is discarded. Each new task gets its own purpose-built window. This is the version that performs best, and is worth aiming for whenever the task is small enough to scope cleanly.
Acceptable. The context is maintained across multiple turns, but maintained deliberately. Long debugging sessions, exploratory work, paired sessions where a human is iterating with the agent in real time, all genuinely benefit from accumulated state, because the accumulated state is part of what makes the next turn good. The discipline here is not to discard the history but to curate it. Summarise. Prune. Compact. Cut the dead ends out before they sediment. Tools like Claude Code have explicit compaction and memory features for exactly this reason.
Bad practice. A single long-running context window left to grow indefinitely. Hours of unrelated work piled on top of each other. The agent's first instructions still sitting there alongside the user's eighty-fourth follow-up, with three contradictions and two abandoned approaches in between. This is the version that feels productive in the moment, because nothing has to be re-explained, and is quietly catastrophic. It is a bit like a bad relationship nobody has ended. The conversation keeps going, every old argument is still in the room, and everything new gets coloured by everything that came before.
Even when the context is being assembled with discipline, there is still the question of how the agent finds the right things to put in it. This is where the current generation of tooling shows its second limit. The primary mechanism a coding agent has for retrieval today is grep, or more accurately ripgrep, the faster regex variant Claude Code wraps as its built-in search tool.
The way that actually works is worth describing precisely, because the picture most people carry of it is too simple. Grep itself does not load whole files into the context window. It runs a regular expression against the file system and returns one of three things: a list of file paths that contain a match, the matched lines with a small window of surrounding context, or a count of matches per file. Cheap, narrow, and on its own not enough for the agent to understand the material it has just located.
What follows is a second step. Once grep has surfaced the candidate files, the agent calls a separate tool, read, to pull file content into the window. Read can take a line range, but in practice it usually pulls the whole file, because three lines of regex context around a match are rarely enough to understand what a function actually does, or what a rule actually says. The combination assembles what the agent then reasons over: grep to locate, read to load.
The same machinery is at work whether the agent is searching the codebase or the markdown documents the team has curated as instructions. Both steps are non-deterministic in either case. The first depends on whether the regex happens to match the right token; rename a concept, choose a synonym, restructure a function, edit a rule into different wording, and the right file may not surface at all. The second depends on the agent's judgement about which of the matched files are worth reading, and how much of each. It is a sophisticated version of throwing a net into the ocean and hoping for the best, and the net is being thrown across two oceans at once: the codebase itself, and the rules that are meant to govern how it gets written. Sometimes the agent catches the right fish. Sometimes it catches the wrong ones, and writes confident code, or follows a confident-but-stale rule, on the strength of the wrong catch.
A non-deterministic retrieval process cannot be trusted to assemble a deterministic context. And as a profession we have not yet given the agent anything better to retrieve from.
The way every AI-native team has tried to use markdown for context has gone through four identifiable evolutions in roughly two years. The first three are where the industry sits today. The fourth is the work that has to come next.
Evolution 1: one file per repo
The earliest pattern was a single instruction document checked into the repository. Each agent vendor settled on its own filename. Anthropic's Claude Code reads CLAUDE.md from the repo root. GitHub Copilot reads .github/copilot-instructions.md. Cursor reads .cursorrules. Other tools have their variants, all in the same essential shape. Most teams set the file up by asking the agent itself to scan the codebase and produce a draft, then edited it down. The file would be loaded into every session that touched the repo, gave the agent a rough map of the architecture and the conventions, and for a short while it worked.
Then it started to grow. Each session added a rule, a clarification, a line about an edge case that bit somebody last Tuesday. Information got duplicated across sections. Occasionally it contradicted itself. After a few months a two-thousand-line CLAUDE.md was unremarkable, and the agent's context window was filling up with instructions before it had begun thinking about the actual problem.
Evolution 2: skills, and the same problem magnified
The natural next move was to break the single file into many smaller ones, loaded selectively rather than all at once. A handful of clever plugins emerged, several of them from Anthropic and the community building around it, that gave teams some control over which document was pulled into the context window and when. The collection acquired the lovely name skills: a folder of markdown documents covering the team's architecture, design decisions, coding standards, security posture, and whatever else seemed worth instructing the agent on.
You have to enjoy the naming. Skills is a wonderful word for what we are gesturing at, and the name has run a little ahead of the substance, in the way names tend to run ahead of substance early in a discipline. A skill, today, is a markdown document with some content in it, sitting in a folder, pulled into the context window when something tells the agent it might be relevant. There is something quite charming about it. We are still in the punch-card era, naming it after what we hope it will become.
The loading mechanism is slightly different from the grep-and-read pattern. Each skill file carries a block of frontmatter describing when it should be considered relevant. The agent reads the frontmatter, decides which skills apply to the task at hand, and pulls the matching ones into the window in their entirety. The selection is per-file rather than per-line, which is a small step forward. The same non-determinism is still in play: whether the right skill loads depends on whether the description in the frontmatter happens to match the shape of the task, and on the agent's judgement about which of several plausibly relevant ones to pull in.
All of this works, until the files start to grow.
Bloat does not go away by being spread across more files. It magnifies. Skills bloat in exactly the way CLAUDE.md bloated, but now across half a dozen documents instead of one. Each session adds a rule, a clarification, an edge case, and no session takes one out, because nobody is paid to take rules out. The collection gets longer. The agent's window fills up earlier. The relevance signal, the one thing that makes the agent useful, gets quieter.
Skills drift in exactly the same way. A rule says the team uses Postgres, three months after the team migrated to DynamoDB. The agent reads the rule, writes the wrong code, and does so confidently, citing a file that has been quietly wrong for a quarter. Often we cannot even trace where the offending instruction came from, because it is buried in one of half a dozen overlapping documents, none of them dated and none of them owned.
Evolution 3: lift the files out of the repo
If the files in the repository are bloating and drifting, the natural next move is to lift them out of the repository entirely. Some teams put their skills in a dedicated repository of their own, where they can be branched, versioned, and reviewed as a unit, and where the same set of rules can serve more than one codebase. Others move to a wiki or a documents portal like Notion, on the grounds that knowledge management deserves its own tool with its own audience. We have tried versions of both as a company.
Both approaches buy you something genuine. A separate repository inherits all of the apparatus of code review: branch protection, ownership, commit history, the ability to roll back a bad change. A wiki gives non-engineers a much friendlier surface to read and contribute on, and the team a cleaner search experience. The trouble is that the underlying problem does not move with the files. Bloat accumulates wherever the documents live, because everyone is busy and the change rate is high. Drift between rule and code happens just the same, because the rules and the code are evolving on different schedules. A wiki sitting outside the repo is in some ways the worst of all worlds: at least the repo had the discipline of code review around it, the wiki has nothing.
What the move actually buys is the opportunity for review discipline. It does not enforce it. And in practice the ceremonies that used to catch this drift have already weakened. The pull request and the code review used to be a particular kind of ritual. Senior engineers read submissions carefully, fed back generously, and used the act of review as the central learning mechanism on a team. I do not see that in my own team any longer. I do not really see it in my own practice.
On a Friday afternoon recently I sat down with a queue of merge requests that had stacked up across the last few days. By the time I had read the third one I had stopped reading the code. I was asking the coding agent to fetch each merge request through its git integration and tell me whether the change was sound. It caught things in some of them I would have missed if I had been on my own. In a couple of cases it told me everything was clean and I merged on its word. The volume coming through is high, the work is more often than not better than I would have written by hand, and the muscle for review has weakened in a way I was not paying attention to until I noticed it had gone. The easiest prompt in the world, at the end of a session, is update the skills to reflect what we just did. I genuinely wonder how often anyone reviews that update before it becomes the next instruction the next agent reads.
Evolution 4: from documents to a knowledge map
The fourth evolution does not start with a new file format. It starts with a different conception of what we are trying to maintain in the first place.
A team's instructions to its agents are not really a pile of documents. They are a map of what the team has decided. Architectural choices, conventions, security stances, the rationale behind a Postgres-to-DynamoDB migration, the reasons a particular service ended up split into three. These are interconnected pieces of knowledge with relationships between them: this decision was made because of that one, this rule depends on that constraint, this convention is in tension with that other one. A flat markdown file collapses those relationships into a paragraph that may or may not survive the next merge. A wiki does the same in a friendlier wrapper. Neither has any way to know what is connected to what.
The right shape of the answer is a knowledge map. The instructions, rules and decisions a team needs the agent to act on stop being lines of text in overlapping markdown files and start being objects in their own right, with identity, ownership, history, and explicit relationships to each other and to the code. They live in a structured store, something Postgres-shaped, which already does most of this work in adjacent domains. Postgres is interesting precisely because it offers three retrieval strategies in the same engine. Structured SQL handles relational queries cleanly, the kind a deterministic process can rely on. Full-text search is the modern equivalent of grep, but applied to a curated corpus rather than the whole file system. Vector search handles the semantic case, when the agent does not know quite what it is looking for and needs the closest match in meaning rather than in wording.
A protocol like MCP lets the agent call into that store and ask precise questions, returning precise answers, rather than hauling whole files into the window in the hope the right paragraph is in there somewhere. The retrieval becomes deterministic. The context becomes the smallest set of things that actually matter for the task.
On top of the structured store sits the obvious next layer. Tooling that watches the rules for bloat and contradiction. Tooling that compares the current rule to the current code and flags drift the moment it appears, rather than the moment it breaks something expensive. A review surface for the instructions themselves, not only for the code those instructions produce. Versioning that treats every change to a rule the way the team treats every change to the code. A user interface a human can sit in front of, edit, and trust.
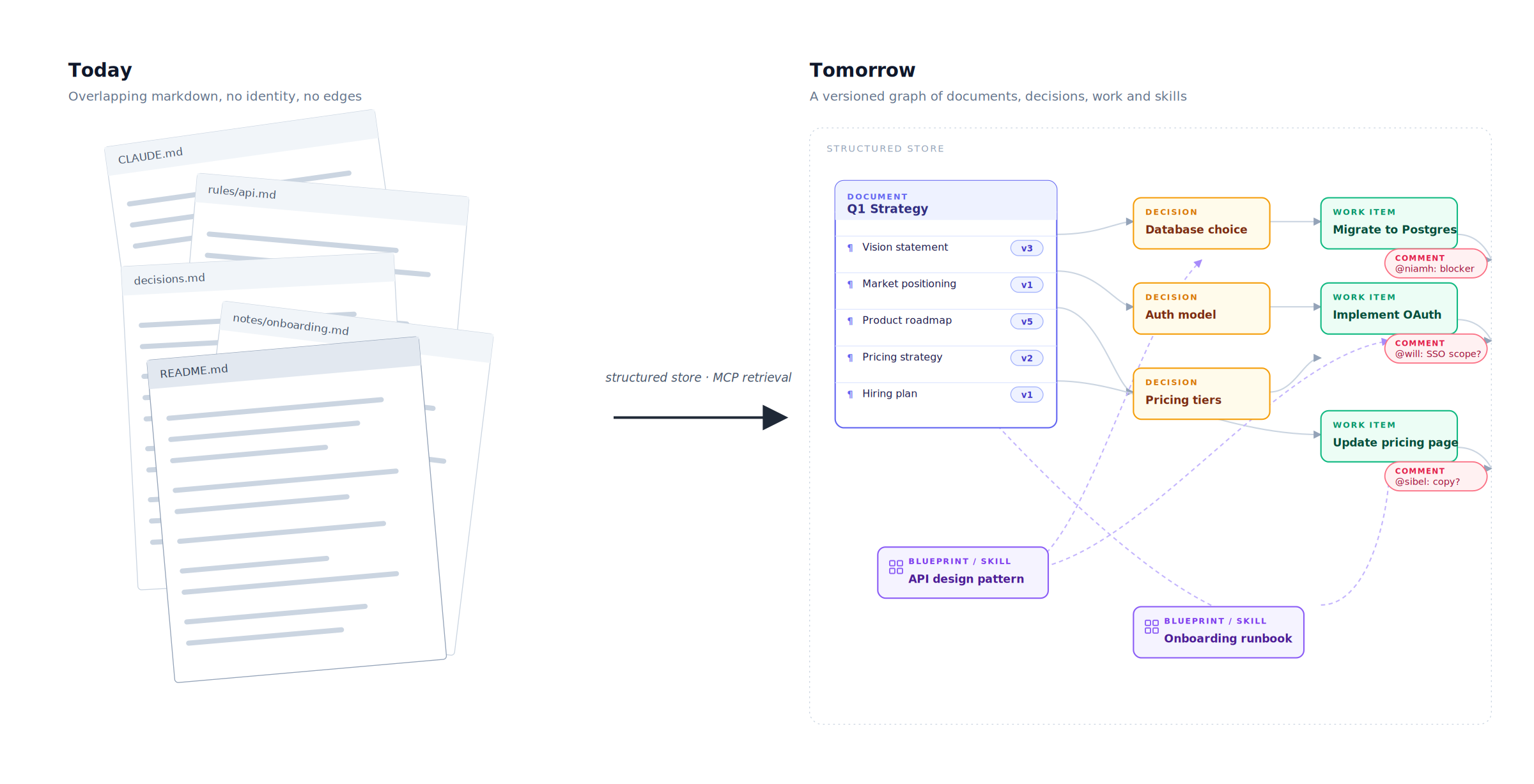
This is broadly the work we have been doing as a company. I will write about specifics elsewhere in the series, and I will be careful to separate what is product-specific from what is generally true.
Ending or beginning?
The pessimistic reading of this whole moment is that it is the end of something. I saw the beginning of the previous arc, in that computer room. Punch cards, then terminals, then home machines, the web, mobile, cloud. Forty years of compounding sophistication in how humans wrote software. Now most of the writing is being done by machines, and the machines communicate with us through a medium that would have looked familiar in 1985. On that reading, the markdown era is the regression and the arc is closing.
The optimistic reading, which I find more persuasive and which I actively prefer, is that markdown is not the destination. It is the punch card. It is what we hand-rolled to communicate with the agent before we had built anything better, and it has served us for the few years we needed it. What replaces it is not another file format. It is a shift in what we are trying to preserve in the first place.
The thing worth preserving is the team's knowledge. The decisions, the reasons behind them, the constraints they were taken under, the relationships between them, everything we collectively know that should outlast any individual session, repository, or developer. Not as a document. As a structured, queryable, versioned map of what is true. A map humans can read, edit, and trust, that agents can call into deterministically, and that drift detection can patrol automatically. Building software in collaboration with AI agents, professionally and over years, will turn out to be mostly the work of building and maintaining that map.
The child in that computer room, if he had been told that punch cards were already nearly obsolete, would not have concluded that software was finished. He would have wanted to know what came next.
Same answer, forty years later.
— Barrie
I am co-founder and CEO of Mindset AI, where we are building Memex AI, a decision and knowledge layer for AI-native engineering teams. This series is the thinking that shapes our product. I will flag it explicitly when an article touches something we build. Most of it is simply where the industry is going, with or without us.